 JavaWeb
JavaWeb
 Spring
Spring
 MyBatis
MyBatis
 linux
linux
 消息队列
消息队列
 JavaSE
JavaSE
 工具
工具
 AI
AI
 搜索
搜索
 dy
dy
Redis集群
Redis集群
1.问题
容量不够,redis如何进行扩容?
并发写操作, redis如何分摊?
另外,主从模式,薪火相传模式,主机宕机,导致ip地址发生变化,应用程序中配置需要修改对应的主机地址、端口等信息。
之前通过代理主机来解决,但是redis3.0中提供了解决方案。就是无中心化集群配置。
2.什么是集群
Redis 集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
3.如何搭建集群
1.删除持久化文件
将rdb,aof文件都删除掉
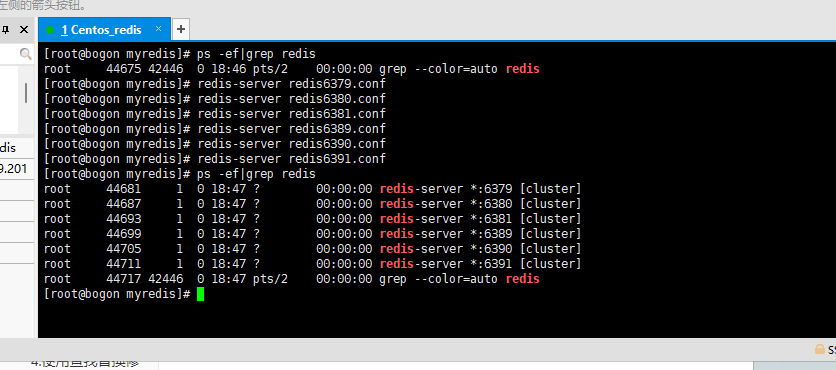
2.制作6个实例,6379,6380,6381,6389,6390,6391
1.配置基本信息
开启daemonize yes
Pid文件名字
指定端口
Log文件名字
Dump.rdb名字
Appendonly 关掉或者换名字
这里由于是在一台主机上模拟集群,在搭建单机redis时,已经配置基本信息,所以不用重复配置,直接使用include引入即可
2.redis cluster配置修改
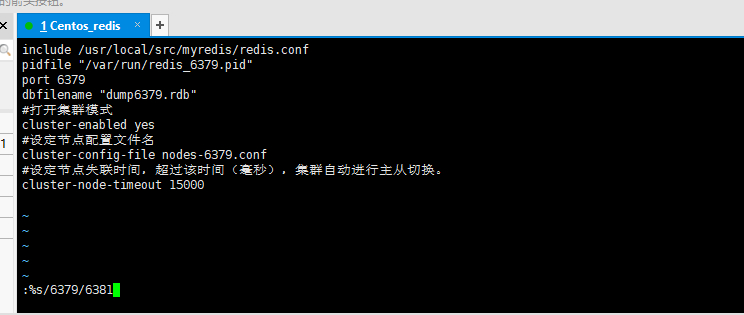
vi redis6379.conf,进行集群配置
include /usr/local/src/myredis/redis.conf
pidfile "/var/run/redis_6379.pid"
port 6379
dbfilename "dump6379.rdb"
#打开集群模式
cluster-enabled yes
#设定节点配置文件名
cluster-config-file nodes-6379.conf
#设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换。
cluster-node-timeout 15000
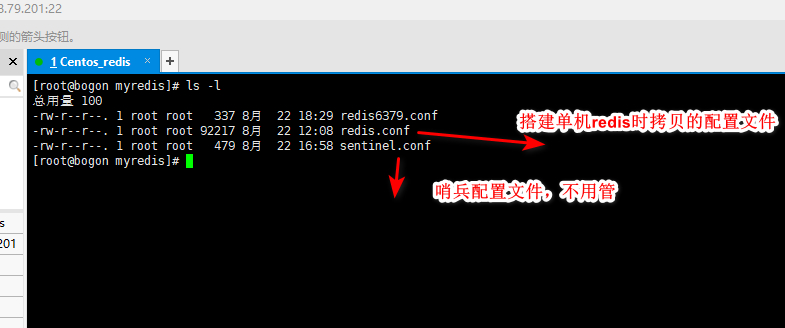
3.修改好redis6379.conf文件作为集群配置模板,拷贝多个redis.conf文件
一台主机,一台从机,正好三组。
[root@bogon myredis]# cp redis6379.conf redis6380.conf
[root@bogon myredis]# cp redis6379.conf redis6381.conf
[root@bogon myredis]# cp redis6379.conf redis6389.conf
[root@bogon myredis]# cp redis6379.conf redis6390.conf
[root@bogon myredis]# cp redis6379.conf redis6391.conf
4.使用查找替换修改另外5个文件
例如::%s/6379/6380
5.启动6个redis服务
6.将六个节点合成一个集群
1.组合之前,请确保所有redis实例启动后,nodes-xxxx.conf文件都生成正常。
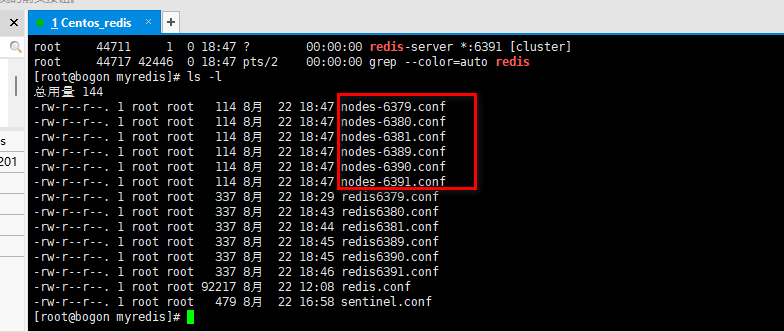
2.将6个节点合成一个集群
此处不要用127.0.0.1, 请用真实IP地址,这里实在一台主机上模拟集群搭建,真实搭建应该写每一台服务器的ip和端口,并在每个服务器的redis解压目录的src目录下执行
--replicas 1 采用最简单的方式配置集群,一台主机,一台从机,正好三组。
#进入redis解压目录下的src目录
cd /usr/local/src/redis-6.2.1/src/
#执行节点合成集群操作
redis-cli --cluster create --cluster-replicas 1 192.168.79.201:6379 192.168.79.201:6380 192.168.79.201:6381 192.168.79.201:6389 192.168.79.201:6390 192.168.79.201:6391
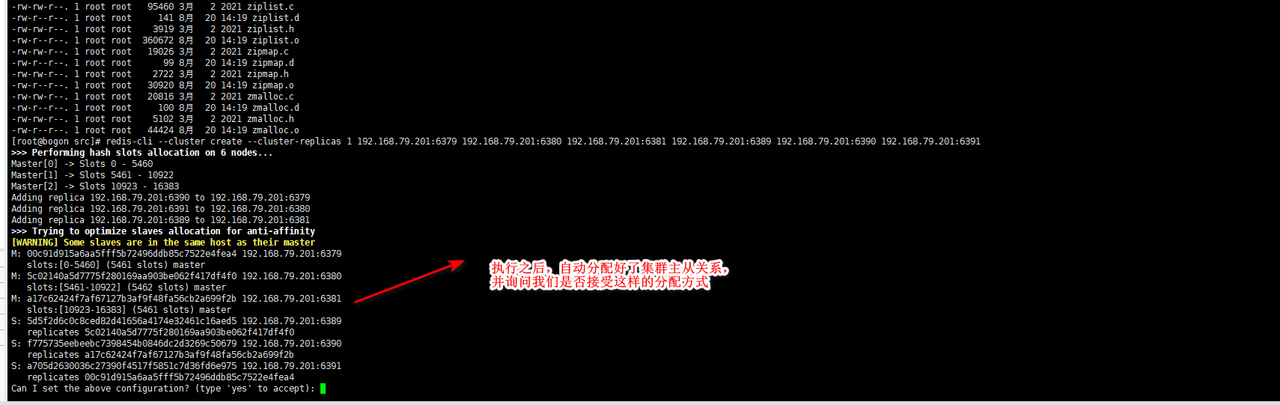
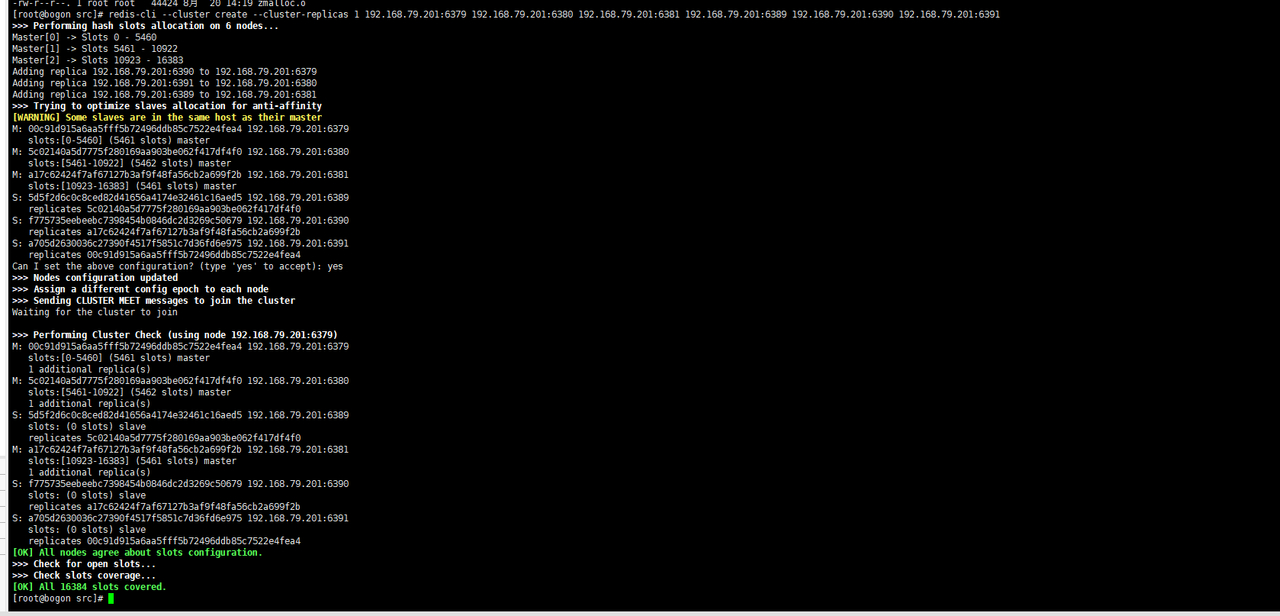
至此,redis集群搭建就算是完成了。
7.-c 采用集群策略连接,设置数据会自动切换到相应的写主机
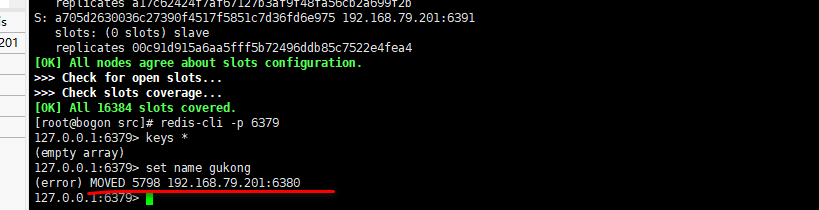
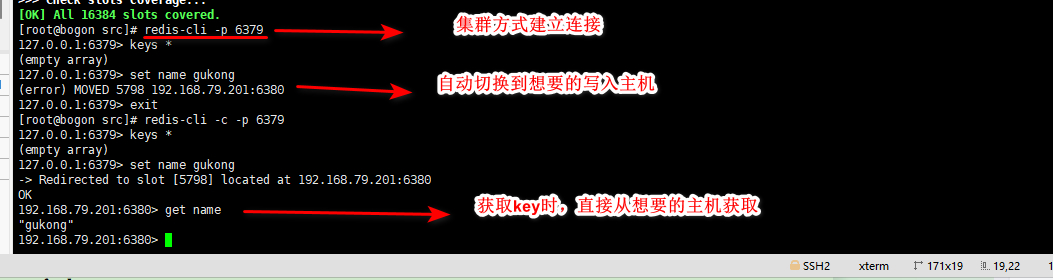
1.普通方式登录
可能直接进入读主机,存储数据时,会出现MOVED重定向操作。所以,应该以集群方式登录。
[root@bogon src]# redis-cli -p 6379
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379> set name gukong
(error) MOVED 5798 192.168.79.201:6380
127.0.0.1:6379> exit
2.采用``redis-cli -c -p 端口号`集群策略连接
[root@bogon src]# redis-cli -c -p 6379
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379> set name gukong
-> Redirected to slot [5798] located at 192.168.79.201:6380
OK
192.168.79.201:6380> get name
"gukong"
192.168.79.201:6380>
8.通过cluster nodes 命令查看集群信息
注意观察主从信息

9.redis cluster 如何分配这六个节点?
一个集群至少要有三个主节点。
选项 --cluster-replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
分配原则尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上。
10.什么是slotsa
一个 Redis 集群包含 16384 个插槽(hash slot), 数据库中的每个键都属于这 16384 个插槽的其中一个,
集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。
集群中的每个节点负责处理一部分插槽。 举个例子, 如果一个集群可以有主节点, 其中:
节点 A 负责处理 0 号至 5460 号插槽。
节点 B 负责处理 5461 号至 10922 号插槽。
节点 C 负责处理 10923 号至 16383 号插槽。
192.168.79.201:6380> set name gukong
OK
#CRC16(age) % 16384 计算出key为age在741号插槽,由A节点(6379)复制
192.168.79.201:6380> set age 11
-> Redirected to slot [741] located at 192.168.79.201:6379
OK
#CRC16(nickname) % 16384 计算出key为nickname在14594号插槽,由C节点(6381)负责
192.168.79.201:6379> set nickname kulilin
-> Redirected to slot [14594] located at 192.168.79.201:6381
OK
192.168.79.201:6381>
4.集群相关操作
1.在集群中录入值
在redis-cli每次录入、查询键值,redis都会计算出该key应该送往的插槽,如果不是该客户端对应服务器的插槽,redis会报错,并告知应前往的redis实例地址和端口。redis-cli客户端提供了 –c 参数实现自动重定向。如 redis-cli -c –p 6379登入后,再录入、查询键值对可以自动重定向。但需要注意的是不在一个slot下的键值,是不能使用mget,mset等多键操作。
192.168.79.201:6381> mset name gukong age 21
(error) CROSSSLOT Keys in request don't hash to the same slot
那么如何解决呢?
可以通过{}来定义组的概念,从而使key中{}内相同内容的键值对放到一个slot中去。其实就是对组的值进行计算,从而确定所属于那个插槽
192.168.79.201:6381> mset name{user} gukong age{user} 24 nickname{user} kakaluote
-> Redirected to slot [5474] located at 192.168.79.201:6380
OK
192.168.79.201:6380> get name{user}
"gukong"
192.168.79.201:6380> get nickname{user}
"kakaluote"
192.168.79.201:6380> get age{user}
"24"
2.查询集群中的值
CLUSTER GETKEYSINSLOT < slot> < count> 返回 count 个 slot 槽中的键。
#cluster keyslot <key> 获取key为:“name{user}”所在的插槽号
192.168.79.201:6380> cluster keyslot name{user}
(integer) 5474
#获取key为:"name"所在的插槽号
192.168.79.201:6380> cluster keyslot name
(integer) 5798
#cluster countkeysinslot 插槽号 获取插槽号为5798的key的总数
192.168.79.201:6380> cluster countkeysinslot 5798
(integer) 1
#cluster getkeysinslot 插槽号,获取插槽号为7474的10个key
192.168.79.201:6380> cluster getkeysinslot 7474 10
(empty array)
#cluster getkeysinslot 插槽号,获取插槽号为5474的19个key
192.168.79.201:6380> cluster getkeysinslot 5474 19
1) "age{user}"
2) "k1{user}"
3) "k2{user}"
4) "k3{user}"
5) "name{user}"
6) "nickname{user}"
3.故障恢复
1.如果主节点下线?从节点能否自动升为主节点? 可以
需要注意的是在前面我们配置redis.conf时设置了集群失联的时间15s,所以要看到效果需要等待15s
include /usr/local/src/myredis/redis.conf
pidfile "/var/run/redis_6379.pid"
port 6379
dbfilename "dump6379.rdb"
#打开集群模式
cluster-enabled yes
#设定节点配置文件名
cluster-config-file nodes-6379.conf
#设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换。
cluster-node-timeout 15000
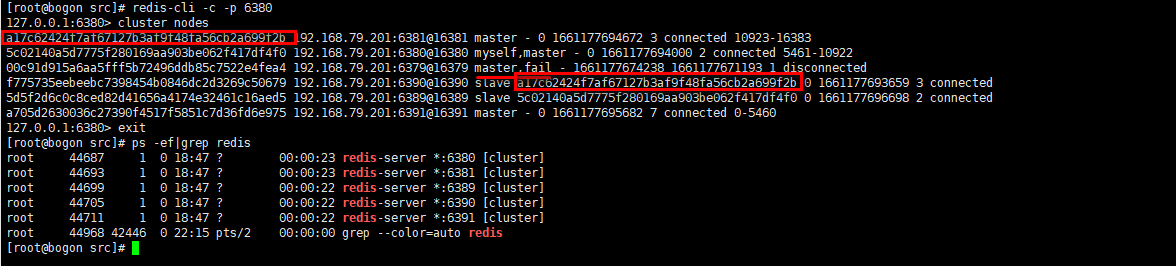
2.主节点恢复后,主从关系会如何? 恢复后的主节点会变成从机
127.0.0.1:6379> cluster nodes
a705d2630036c27390f4517f5851c7d36fd6e975 192.168.79.201:6391@16391 master - 0 1661178470000 7 connected 0-5460
f775735eebeebc7398454b0846dc2d3269c50679 192.168.79.201:6390@16390 slave a17c62424f7af67127b3af9f48fa56cb2a699f2b 0 1661178472935 3 connected
5c02140a5d7775f280169aa903be062f417df4f0 192.168.79.201:6380@16380 master - 0 1661178471924 2 connected 5461-10922
#主节点恢复之后作为6391得从机
00c91d915a6aa5fff5b72496ddb85c7522e4fea4 192.168.79.201:6379@16379 myself,slave a705d2630036c27390f4517f5851c7d36fd6e975 0 1661178464000 7 connected
a17c62424f7af67127b3af9f48fa56cb2a699f2b 192.168.79.201:6381@16381 master - 0 1661178472000 3 connected 10923-16383
5d5f2d6c0c8ced82d41656a4174e32461c16aed5 192.168.79.201:6389@16389 slave 5c02140a5d7775f280169aa903be062f417df4f0 0 1661178471000 2 connected
127.0.0.1:6379>
3.如果所有某一段插槽的主从节点都宕掉,redis服务是否还能继续?
(1)如果某一段插槽的主从都挂掉,而cluster-require-full-coverage 为yes ,那么 ,整个集群都挂掉
(2)如果某一段插槽的主从都挂掉,而cluster-require-full-coverage 为no ,那么,该插槽数据全都不能使用,也无法存储。
取决于redis.conf中的参数 cluster-require-full-coverage值得配置
# However sometimes you want the subset of the cluster which is working,
# to continue to accept queries for the part of the key space that is still
# covered. In order to do so, just set the cluster-require-full-coverage
# option to no.
#
# cluster-require-full-coverage yes
5.集群的Jedis开发
即使连接的不是主机,集群会自动切换主机存储。主机写,从机读。
无中心化主从集群。无论从哪台主机写的数据,其他主机上都能读到数据。
public class JedisClusterTest {
public static void main(String[] args) {
Set<HostAndPort> set = new HashSet<HostAndPort>();
//连接任意一台均可
set.add(new HostAndPort("192.168.79.201", 6379));
JedisCluster jedisCluster = new JedisCluster(set);
jedisCluster.set("name", "kakaluote");
System.out.println(jedisCluster.get("k1"));
}
}
6.redis集群的优点和缺点
优点
1.实现扩容
2.分摊压力
3.无中心配置相对简单
缺点
1.多键操作是不被支持的
2.多键的Redis事务是不被支持的。lua脚本不被支持
3.由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而代理或者客户端分片的方案想要迁移至redis cluster,需要整体迁移而不是逐步过渡,复杂度较大。