 JavaWeb
JavaWeb
 Spring
Spring
 MyBatis
MyBatis
 linux
linux
 消息队列
消息队列
 JavaSE
JavaSE
 工具
工具
 AI
AI
 搜索
搜索
 dy
dy
SpringBoot整合Kafka

SpringBoot整合Kafka
1.快速入门
1.1引入依赖,搭建maven工程
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- 引入 Spring-Kafka 依赖 -->
<!-- 已经内置 kafka-clients 依赖,所以无需重复引入 -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.3.3.RELEASE</version>
</dependency>
<!-- 实现对 JSON 的自动化配置 -->
<!-- 因为,Kafka 对复杂对象的 Message 序列化时,我们会使用到 JSON -->
<!--
同时,spring-boot-starter-json 引入了 spring-boot-starter ,而 spring-boot-starter 又引入了 spring-boot-autoconfigure 。
spring-boot-autoconfigure 实现了 Spring-Kafka 的自动化配置
-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-json</artifactId>
</dependency>
<!-- 方便等会写单元测试 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
1.2应用配置
spring:
# Kafka 配置项,对应 KafkaProperties 配置类
kafka:
bootstrap-servers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
# Kafka Producer 配置项
producer:
acks: 1 # 0-不应答。1-leader 应答。all-所有 leader 和 follower 应答。
retries: 3 # 发送失败时,重试发送的次数
key-serializer: org.apache.kafka.common.serialization.StringSerializer # 消息的 key 的序列化
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer # 消息的 value 的序列化
# Kafka Consumer 配置项
consumer:
auto-offset-reset: earliest # 设置消费者分组最初的消费进度为 earliest 。可参考博客 https://blog.csdn.net/lishuangzhe7047/article/details/74530417 理解
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
# 配置信任com.llp.kafka.message包下的消息类,
#因为 JsonDeserializer 在反序列化消息时,考虑到安全性,只反序列化成信任的 Message 类
properties:
spring:
json:
trusted:
packages: com.llp.kafka.message
# Kafka Consumer Listener 监听器配置
listener:
missing-topics-fatal: false # 消费监听接口监听的主题不存在时,默认会报错。所以通过设置为 false ,解决报错
logging:
level:
org:
springframework:
kafka: ERROR # spring-kafka INFO 日志太多了,所以我们限制只打印 ERROR 级别
apache:
kafka: ERROR # kafka INFO 日志太多了,所以我们限制只打印 ERROR 级别
1.3代码实现
启动类
@SpringBootApplication
public class KafkaApplication {
public static void main(String[] args) {
SpringApplication.run(KafkaApplication.class,args);
}
}
消息类
@Data
public class Demo01Message {
public static final String TOPIC = "demo1";
private Integer id;
private String content;
}
生产者
/**
* 生产者
*/
@Component
public class Demo01Producer {
@Resource
private KafkaTemplate<Object, Object> kafkaTemplate;
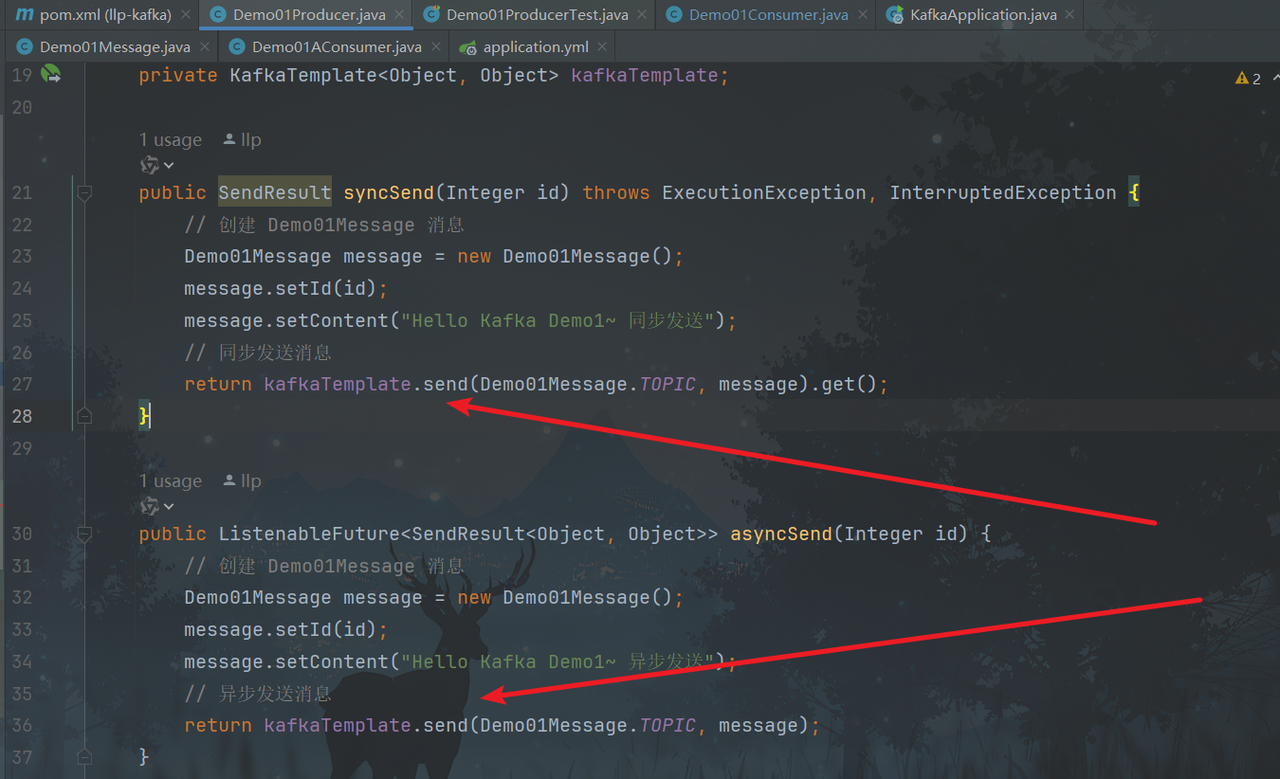
public SendResult syncSend(Integer id) throws ExecutionException, InterruptedException {
// 创建 Demo01Message 消息
Demo01Message message = new Demo01Message();
message.setId(id);
message.setContent("Hello Kafka Demo1~ 同步发送");
// 同步发送消息
return kafkaTemplate.send(Demo01Message.TOPIC, message).get();
}
public ListenableFuture<SendResult<Object, Object>> asyncSend(Integer id) {
// 创建 Demo01Message 消息
Demo01Message message = new Demo01Message();
message.setId(id);
message.setContent("Hello Kafka Demo1~ 异步发送");
// 异步发送消息
return kafkaTemplate.send(Demo01Message.TOPIC, message);
}
}
消费者1
/**
* 消费者 ,建议一个类,对应一个方法
*/
@Component
@Slf4j
public class Demo01Consumer {
/**
* 建议一个消费者分组,仅消费一个 Topic 。这样做会有个好处:每个消费者分组职责单一,只消费一个 Topic 。
* @param message
*/
@KafkaListener(topics = Demo01Message.TOPIC,
groupId = "demo01-consumer-group-" + Demo01Message.TOPIC)
public void onMessage(Demo01Message message) {
log.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), message);
}
//@KafkaListeners({@KafkaListener(topics = Demo01Message.TOPIC,
// groupId = "demo01-consumer-group-" + Demo01Message.TOPIC)})
//public void onMessage1(Demo01Message message) {
// log.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), message);
//}
}
消费者2
@Slf4j
@Component
public class Demo01AConsumer {
@KafkaListener(topics = Demo01Message.TOPIC,
groupId = "demo01-A-consumer-group-" + Demo01Message.TOPIC)
public void onMessage(ConsumerRecord<Integer, String> record) {
log.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), record);
}
}
**ps:**这里两个消费者归属于不同的消费者组,但都是同一个主题进行消费,kafka集群消费(Clustering):集群消费模式下,相同 Consumer Group 的每个 Consumer 实例平均分摊消息。
通过集群消费的机制,我们可以实现针对相同 Topic ,不同消费者分组实现各自的业务逻辑。例如说:用户注册成功时,发送一条 Topic 为 "USER_REGISTER" 的消息。然后,不同模块使用不同的消费者分组,订阅该 Topic ,实现各自的拓展逻辑:
- 积分模块:判断如果是手机注册,给用户增加 20 积分。
- 优惠劵模块:因为是新用户,所以发放新用户专享优惠劵。
- 站内信模块:因为是新用户,所以发送新用户的欢迎语的站内信。
- ... 等等
**ConsumerRecord: ** Kafka 内置的 类。通过 ConsumerRecord 类,我们可以获取到消费的消息的更多信息,例如说消息的所属队列、创建时间等等属性,不过消息的内容(value)就需要自己去反序列化。当然,一般情况下,我们不会使用 ConsumerRecord 类。
测试类
@RunWith(SpringRunner.class)
@SpringBootTest(classes = KafkaApplication.class)
@Slf4j
public class Demo01ProducerTest {
@Autowired
private Demo01Producer producer;
@Test
public void testSyncSend() throws ExecutionException, InterruptedException {
int id = (int) (System.currentTimeMillis() / 1000);
SendResult result = producer.syncSend(id);
log.info("[testSyncSend][发送编号:[{}] 发送结果:[{}]]", id, result);
// 阻塞等待,保证消费
new CountDownLatch(1).await();
}
@Test
public void testASyncSend() throws InterruptedException {
int id = (int) (System.currentTimeMillis() / 1000);
producer.asyncSend(id).addCallback(new ListenableFutureCallback<SendResult<Object, Object>>() {
@Override
public void onFailure(Throwable e) {
log.info("[testASyncSend][发送编号:[{}] 发送异常]]", id, e);
}
@Override
public void onSuccess(SendResult<Object, Object> result) {
log.info("[testASyncSend][发送编号:[{}] 发送成功,结果为:[{}]]", id, result);
}
});
// 阻塞等待,保证消费
new CountDownLatch(1).await();
}
}
同步发送
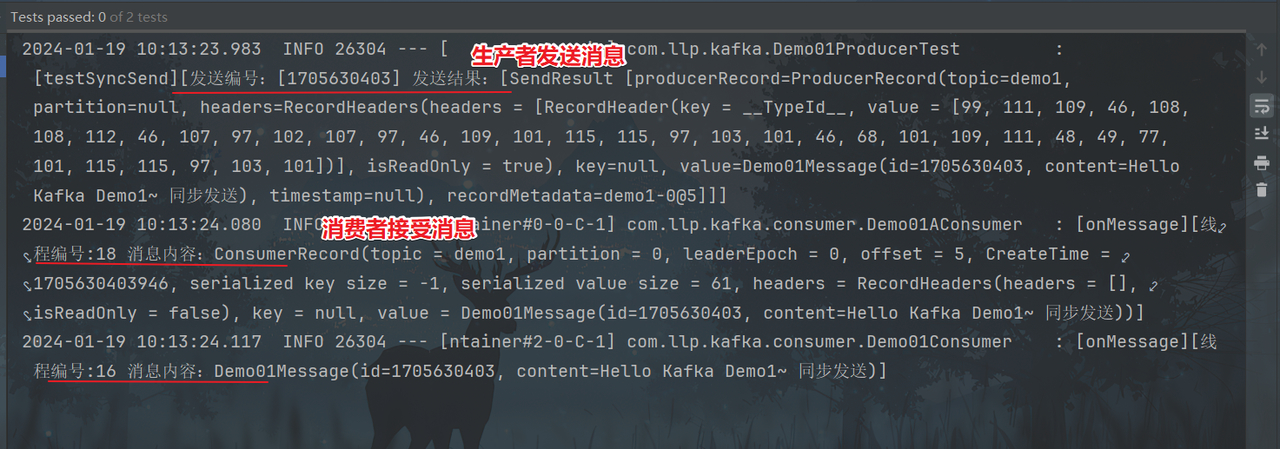
异步发送
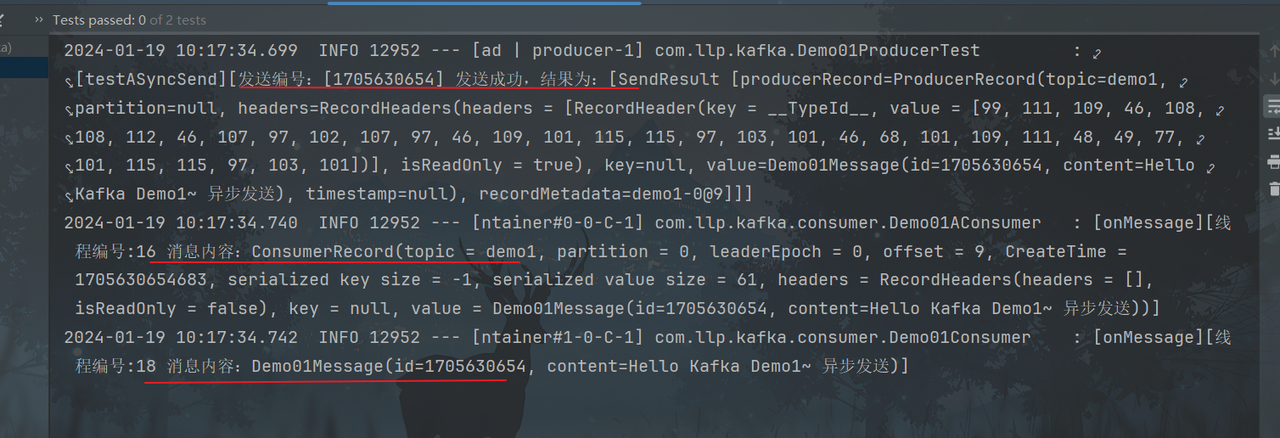
2. @KafkaListener
/**
* 监听的 Topic 数组
*/
String[] topics() default {};
/**
* 监听的 Topic 表达式
*/
String topicPattern() default "";
/**
* @TopicPartition 注解的数组。每个 @TopicPartition 注解,可配置监听的 Topic、队列、消费的开始位置
*/
TopicPartition[] topicPartitions() default {};
/**
* 消费者分组
*/
String groupId() default "";
/**
* 使用消费异常处理器 KafkaListenerErrorHandler 的 Bean 名字
*/
String errorHandler() default "";
/**
* 自定义消费者监听器的并发数,比如配置concurrency=2则在消费时kafka会创建两个消费者去消费消息,比如topic有10个分区,每个消费者分5个分区进行消费,结合实际情况设置,如果值设置的过大会导致kafka空轮询,多余的消费者也分配不到消息
*
*/
String concurrency() default "";
/**
* 是否自动启动监听器。默认情况下,为 true 自动启动。
*/
String autoStartup() default "";
/**
* Kafka Consumer 拓展属性。
*/
String[] properties() default {};
@KafkaListener 注解的不常用属性如下:
/**
* 唯一标识
*/
String id() default "";
/**
* id 唯一标识的前缀
*/
String clientIdPrefix() default "";
/**
* 当 groupId 未设置时,是否使用 id 作为 groupId
*/
boolean idIsGroup() default true;
/**
* 使用的 KafkaListenerContainerFactory Bean 的名字。
* 若未设置,则使用默认的 KafkaListenerContainerFactory Bean 。
*/
String containerFactory() default "";
/**
* 所属 MessageListenerContainer Bean 的名字。
*/
String containerGroup() default "";
/**
* 真实监听容器的 Bean 名字,需要在名字前加 "__" 。
*/
String beanRef() default "__listener";
@KafkaListeners 运行配置多个@KafkaListener
@KafkaListeners({@KafkaListener(topics = Demo01Message.TOPIC,
groupId = "demo01-consumer-group-" + Demo01Message.TOPIC)})
public void onMessage1(Demo01Message message) {
log.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), message);
}
3.批量发送消息
kafka和rocketMq不同,并没有提供批量发送消息的api,而是通过配置的方式来实现消息的批量发送
3.1 修改配置文件
spring:
# Kafka 配置项,对应 KafkaProperties 配置类
kafka:
bootstrap-servers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
# Kafka Producer 配置项
producer:
acks: 1 # 0-不应答。1-leader 应答。all-所有 leader 和 follower 应答。
retries: 3 # 发送失败时,重试发送的次数
key-serializer: org.apache.kafka.common.serialization.StringSerializer # 消息的 key 的序列化
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer # 消息的 value 的序列化
batch-size: 16384 # 每次批量发送消息的最大数量 16M,默认16k
buffer-memory: 33554432 # 每次批量发送消息的最大内存 32G,默认32M
properties:
linger:
ms: 3000 # 批处理延迟时间上限。这里配置为 3 * 1000 ms 过后,不管是否消息数量是否到达 batch-size 或者消息大小到达 buffer-memory 后,都直接发送一次请求。
# Kafka Consumer 配置项
consumer:
auto-offset-reset: earliest # 设置消费者分组最初的消费进度为 earliest 。可参考博客 https://blog.csdn.net/lishuangzhe7047/article/details/74530417 理解
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
properties:
spring:
json:
trusted:
packages: com.llp.kafka.message
# Kafka Consumer Listener 监听器配置
listener:
missing-topics-fatal: false # 消费监听接口监听的主题不存在时,默认会报错。所以通过设置为 false ,解决报错
logging:
level:
org:
springframework:
kafka: ERROR # spring-kafka INFO 日志太多了,所以我们限制只打印 ERROR 级别
apache:
kafka: ERROR # kafka INFO 日志太多了,所以我们限制只打印 ERROR 级别
**PS: ** Producer 批量发送的三个条件:
spring.kafka.producer.batch-size对发送到分区的多个记录进行批处理时的默认批处理大小(以字节为单位)默认16Kspring.kafka.producer.buffer-memory配置缓冲区的总大小,默认32Mspring.kafka.producer.properties.linger.ms配置生产者发送消息之前延迟多长时间在进行发送,默认0s
具体应该如何配置,还是要结合实际情况,batch-size和buffer-memory配置的适当大一些有利于提高kafka的执行效率,减少GC但也对服务器内存要求较高
另外batch-size和linger.ms是二选一的,只要满足其中一个条件就会进行发送
3.2代码实现
消息类
@Data
public class Demo02Message {
public static final String TOPIC = "DEMO_012";
/**
* 编号
*/
private Integer id;
/**
* 内容
*/
private String content;
}
生产者
@Component
public class Demo02Producer {
@Resource
private KafkaTemplate<Object, Object> kafkaTemplate;
public ListenableFuture<SendResult<Object, Object>> asyncSend(Integer id) {
// 创建 Demo02Message 消息
Demo02Message message = new Demo02Message();
message.setId(id);
// 异步发送消息
return kafkaTemplate.send(Demo02Message.TOPIC, message);
}
}
消费者
@Component
@Slf4j
public class Demo02Consumer {
@KafkaListener(topics = Demo02Message.TOPIC,
groupId = "demo02-consumer-group-" + Demo02Message.TOPIC)
public void onMessage(Demo02Message message) {
log.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), message);
}
}
测试类
@RunWith(SpringRunner.class)
@SpringBootTest(classes = KafkaApplication.class)
@Slf4j
public class Demo02ProducerTest {
@Autowired
private Demo02Producer producer;
@Test
public void testASyncSend() throws InterruptedException {
log.info("[testASyncSend][开始执行]");
for (int i = 0; i < 3; i++) {
int id = (int) (System.currentTimeMillis() / 1000);
producer.asyncSend(id).addCallback(new ListenableFutureCallback<SendResult<Object, Object>>() {
@Override
public void onFailure(Throwable e) {
log.info("[testASyncSend][发送编号:[{}] 发送异常]]", id, e);
}
@Override
public void onSuccess(SendResult<Object, Object> result) {
log.info("[testASyncSend][发送编号:[{}] 发送成功,结果为:[{}]]", id, result);
}
});
// 故意每条消息之间,隔离 1 秒
Thread.sleep( 1000L);
}
// 阻塞等待,保证消费
new CountDownLatch(1).await();
}
}
测试结果
// 打印 testASyncSend 方法开始执行的日志
2024-01-19 10:51:24.630 INFO 19668 --- [ main] com.llp.kafka.Demo02ProducerTest : [testASyncSend][开始执行]
// 三秒后满足配置的linger.ms生产者发送消息的延迟时间3秒, testASyncSend 方法开始执行的日志
2024-01-19 10:51:28.044 INFO 19668 --- [ad | producer-1] com.llp.kafka.Demo02ProducerTest : [testASyncSend][发送编号:[1705632684] 发送成功,结果为:[SendResult [producerRecord=ProducerRecord(topic=DEMO_012, partition=null, headers=RecordHeaders(headers = [RecordHeader(key = __TypeId__, value = [99, 111, 109, 46, 108, 108, 112, 46, 107, 97, 102, 107, 97, 46, 109, 101, 115, 115, 97, 103, 101, 46, 68, 101, 109, 111, 48, 50, 77, 101, 115, 115, 97, 103, 101])], isReadOnly = true), key=null, value=Demo02Message(id=1705632684, content=null), timestamp=null), recordMetadata=DEMO_012-0@0]]]
2024-01-19 10:51:28.045 INFO 19668 --- [ad | producer-1] com.llp.kafka.Demo02ProducerTest : [testASyncSend][发送编号:[1705632686] 发送成功,结果为:[SendResult [producerRecord=ProducerRecord(topic=DEMO_012, partition=null, headers=RecordHeaders(headers = [RecordHeader(key = __TypeId__, value = [99, 111, 109, 46, 108, 108, 112, 46, 107, 97, 102, 107, 97, 46, 109, 101, 115, 115, 97, 103, 101, 46, 68, 101, 109, 111, 48, 50, 77, 101, 115, 115, 97, 103, 101])], isReadOnly = true), key=null, value=Demo02Message(id=1705632686, content=null), timestamp=null), recordMetadata=DEMO_012-0@1]]]
2024-01-19 10:51:28.046 INFO 19668 --- [ad | producer-1] com.llp.kafka.Demo02ProducerTest : [testASyncSend][发送编号:[1705632687] 发送成功,结果为:[SendResult [producerRecord=ProducerRecord(topic=DEMO_012, partition=null, headers=RecordHeaders(headers = [RecordHeader(key = __TypeId__, value = [99, 111, 109, 46, 108, 108, 112, 46, 107, 97, 102, 107, 97, 46, 109, 101, 115, 115, 97, 103, 101, 46, 68, 101, 109, 111, 48, 50, 77, 101, 115, 115, 97, 103, 101])], isReadOnly = true), key=null, value=Demo02Message(id=1705632687, content=null), timestamp=null), recordMetadata=DEMO_012-0@2]]]
//生产者推送三条消息,消费者消费到三条消息
2024-01-19 10:51:28.081 INFO 19668 --- [ntainer#2-0-C-1] com.llp.kafka.consumer.Demo02Consumer :
[onMessage][线程编号:16 消息内容:Demo02Message(id=1705632684, content=null)]
2024-01-19 10:51:28.081 INFO 19668 --- [ntainer#2-0-C-1] com.llp.kafka.consumer.Demo02Consumer : [onMessage][线程编号:16 消息内容:Demo02Message(id=1705632686, content=null)]
2024-01-19 10:51:28.081 INFO 19668 --- [ntainer#2-0-C-1] com.llp.kafka.consumer.Demo02Consumer : [onMessage][线程编号:16 消息内容:Demo02Message(id=1705632687, content=null)]
4.批量消费消息
在一些业务场景下,我们希望使用 Consumer 批量消费消息,提高消费速度。要注意,Consumer 的批量消费消息,和 Producer 的批量发送消息没有关联
4.1修改配置文件
spring:
# Kafka 配置项,对应 KafkaProperties 配置类
kafka:
bootstrap-servers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
# Kafka Producer 配置项
producer:
acks: 1 # 0-不应答。1-leader 应答。all-所有 leader 和 follower 应答。
retries: 3 # 发送失败时,重试发送的次数
key-serializer: org.apache.kafka.common.serialization.StringSerializer # 消息的 key 的序列化
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer # 消息的 value 的序列化
batch-size: 16384 # 每次批量发送消息的最大数量 16M,默认16k
buffer-memory: 33554432 # 每次批量发送消息的最大内存 32G,默认32M
properties:
linger:
ms: 3000 # 批处理延迟时间上限。这里配置为 30 * 1000 ms 过后,不管是否消息数量是否到达 batch-size 或者消息大小到达 buffer-memory 后,都直接发送一次请求。
# Kafka Consumer 配置项
consumer:
auto-offset-reset: earliest # 设置消费者分组最初的消费进度为 earliest 。可参考博客 https://blog.csdn.net/lishuangzhe7047/article/details/74530417 理解
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
fetch-max-wait: 10000 # poll 一次拉取的阻塞的最大时长,单位:毫秒。这里指的是阻塞拉取需要满足至少 fetch-min-size 大小的消息
fetch-min-size: 10 # poll 一次消息拉取的最小数据量,单位:字节
max-poll-records: 100 # poll 一次消息拉取的最大消息的条数
properties:
spring:
json:
trusted:
packages: com.llp.kafka.message
# Kafka Consumer Listener 监听器配置
listener:
type: batch
missing-topics-fatal: false # 消费监听接口监听的主题不存在时,默认会报错。所以通过设置为 false ,解决报错
logging:
level:
org:
springframework:
kafka: ERROR # spring-kafka INFO 日志太多了,所以我们限制只打印 ERROR 级别
apache:
kafka: ERROR # kafka INFO 日志太多了,所以我们限制只打印 ERROR 级别
和之前的单条消费消息,相比增加了四个配置项
spring.kafka.listener.type监听器类型,默认为 SINGLE ,只监听单条消息。这里我们配置 BATCH ,监听多条消息,批量消费spring.kafka.consumer.max-poll-recordspoll 一次拉取的阻塞的最大时长,单位:毫秒。这里指的是阻塞拉取需要满足至少 fetch-min-size 大小的消息spring.kafka.consumer.fetch-min-sizepoll 一次消息拉取的最小数据量,单位:字节spring.kafka.consumer.fetch-max-waitpoll 一次消息拉取的最大消息的条数
4.2 代码实现
消息类
@Data
public class Demo02Message {
public static final String TOPIC = "DEMO_012";
/**
* 编号
*/
private Integer id;
/**
* 内容
*/
private String content;
}
生产者
@Component
public class Demo02Producer {
@Resource
private KafkaTemplate<Object, Object> kafkaTemplate;
public ListenableFuture<SendResult<Object, Object>> asyncSend(Integer id) {
// 创建 Demo02Message 消息
Demo02Message message = new Demo02Message();
message.setId(id);
// 异步发送消息
return kafkaTemplate.send(Demo02Message.TOPIC, message);
}
}
消费者
@Component
@Slf4j
public class Demo02Consumer {
// @KafkaListener(topics = Demo02Message.TOPIC,
// groupId = "demo02-consumer-group-" + Demo02Message.TOPIC)
// public void onMessage(Demo02Message message) {
// log.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), message);
// }
/**
* 批量消费消息,和单条消费相比Demo02Message message 改成了 List<Demo02Message> messages
* 在配置文件中指定了每次最大拉取消息数量是100,所有这里每次消费List的最大数量就是100
* 比如现在有101条消息,那么就打印的日志应该是两条
*/
@KafkaListener(topics = Demo02Message.TOPIC,
groupId = "demo02-consumer-group-" + Demo02Message.TOPIC)
public void onMessage(List<Demo02Message> messages) {
log.info("[onMessage][线程编号:{} 消息数量:{}]", Thread.currentThread().getId(), messages.size());
}
}
测试类
@RunWith(SpringRunner.class)
@SpringBootTest(classes = KafkaApplication.class)
@Slf4j
public class Demo03ProducerTest {
@Autowired
private Demo02Producer producer;
@Test
public void testASyncSend() throws InterruptedException {
log.info("[testASyncSend][开始执行]");
for (int i = 0; i < 101; i++) {
int id = (int) (System.currentTimeMillis() / 1000);
producer.asyncSend(id).addCallback(new ListenableFutureCallback<SendResult<Object, Object>>() {
@Override
public void onFailure(Throwable e) {
log.info("[testASyncSend][发送编号:[{}] 发送异常]]", id, e);
}
@Override
public void onSuccess(SendResult<Object, Object> result) {
log.info("[testASyncSend][发送编号:[{}] 发送成功,结果为:[{}]]", id, result);
}
});
}
// 阻塞等待,保证消费
new CountDownLatch(1).await();
}
}
测试结果
2024-01-19 11:19:16.091 INFO 5876 --- [ntainer#2-0-C-1] com.llp.kafka.consumer.Demo02Consumer : [onMessage][线程编号:16 消息数量:100]
2024-01-19 11:19:16.094 INFO 5876 --- [ntainer#2-0-C-1] com.llp.kafka.consumer.Demo02Consumer : [onMessage][线程编号:16 消息数量:1]
5.消费重试
Spring-Kafka 提供消费重试的机制。在消息消费失败的时候,Spring-Kafka 会通过消费重试机制,重新投递该消息给 Consumer ,让 Consumer 有机会重新消费消息,实现消费成功。当然,Spring-Kafka 并不会无限重新投递消息给 Consumer 重新消费,而是在默认情况下,达到 N 次重试次数时,Consumer 还是消费失败时,该消息就会进入到死信队列。
5.1KafkaConfiguration
@Configuration
public class KafkaConfiguration {
@Bean
@Primary
public ErrorHandler kafkaErrorHandler(KafkaTemplate<?, ?> template) {
// <1> 创建 DeadLetterPublishingRecoverer 对象
ConsumerRecordRecoverer recoverer = new DeadLetterPublishingRecoverer(template);
// <2> 创建 FixedBackOff 对象
BackOff backOff = new FixedBackOff(10 * 1000L, 3L);
// <3> 创建 SeekToCurrentErrorHandler 对象
return new SeekToCurrentErrorHandler(recoverer, backOff);
}
/**
* 消息的批量消费失败的消费重试处理,但不支持死信队列
*/
// Bean
// @Primary
// public BatchErrorHandler kafkaBatchErrorHandler() {
// // 创建 SeekToCurrentBatchErrorHandler 对象
// SeekToCurrentBatchErrorHandler batchErrorHandler = new SeekToCurrentBatchErrorHandler();
// // 创建 FixedBackOff 对象
// BackOff backOff = new FixedBackOff(10 * 1000L, 3L);
// batchErrorHandler.setBackOff(backOff);
// // 返回
// return batchErrorHandler;
// }
}
Spring-Kafka 的消费重试功能,通过实现自定义的 SeekToCurrentErrorHandler ,在 Consumer 消费消息异常的时候,进行拦截处理:
在重试小于最大次数时,重新投递该消息给 Consumer ,让 Consumer 有机会重新消费消息,实现消费成功。
在重试到达最大次数时,Consumer 还是消费失败时,该消息就会发送到死信队列。例如说,我们测试的 Topic 是 "DEMO_04" ,
则其对应的死信队列的 Topic 就是 "DEMO_04.DLT" ,即在原有 Topic 加上 .DLT 后缀,就是其死信队列的 Topic 。
<1> 处,创建 DeadLetterPublishingRecoverer 对象,它负责实现,在重试到达最大次数时,Consumer 还是消费失败时,该消息就会发送到死信队列。
<2> 处,创建 FixedBackOff 对象。这里,我们配置了重试 3 次,每次固定间隔 10 秒。
当然也可以选择 BackOff 的另一个子类 ExponentialBackOff 实现,提供指数递增的间隔时间。
<3> 处,创建 SeekToCurrentErrorHandler 对象,负责处理异常,串联整个消费重试的整个过程。
5.2代码实现
消息类
@Data
public class Demo04Message {
public static final String TOPIC = "DEMO_04";
/**
* 编号
*/
private Integer id;
/**
* 内容
*/
private String content;
}
生产者
@Component
public class Demo04Producer {
@Resource
private KafkaTemplate<Object, Object> kafkaTemplate;
public SendResult syncSend(Integer id) throws ExecutionException, InterruptedException {
// 创建 Demo04Message 消息
Demo04Message message = new Demo04Message();
message.setId(id);
// 同步发送消息
return kafkaTemplate.send(Demo04Message.TOPIC, message).get();
}
}
消费者
@Component
@Slf4j
public class Demo04Consumer {
private AtomicInteger count = new AtomicInteger(0);
@KafkaListener(topics = Demo04Message.TOPIC,
groupId = "demo04-consumer-group-" + Demo04Message.TOPIC)
public void onMessage(Demo04Message message) {
log.info("消费重试");
log.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), message);
// <X> 注意,此处抛出一个 RuntimeException 异常,模拟消费失败
throw new RuntimeException("我就是故意抛出一个异常");
}
}
测试类
@RunWith(SpringRunner.class)
@SpringBootTest(classes = KafkaApplication.class)
@Slf4j
public class Demo04ProducerTest {
@Autowired
private Demo04Producer producer;
@Test
public void testSyncSend() throws ExecutionException, InterruptedException {
int id = (int) (System.currentTimeMillis() / 1000);
SendResult result = producer.syncSend(id);
log.info("[testSyncSend][发送编号:[{}] 发送结果:[{}]]", id, result);
// 阻塞等待,保证消费
new CountDownLatch(1).await();
}
}
6.顺序消费
我们先来一起了解下顺序消息的顺序消息的定义:
- 普通顺序消息 :Producer 将相关联的消息发送到相同的消息队列。
- 完全严格顺序 :在【普通顺序消息】的基础上,Consumer 严格顺序消费。
kafka在 Consumer 消费消息时,天然就支持按照 Topic 下的 Partition 下的消息,顺序消费
kafka中DefaultPartitioner 默认分区策略
全路径类名:org.apache.kafka.clients.producer.internals.DefaultPartitioner
- 如果消息中指定了分区,则使用它
- 如果未指定分区但存在key,则根据序列化key使用murmur2哈希算法对分区数取模。
- 如果不存在分区或key,则会使用粘性分区策略
因此在kafka中实现顺序消费只需要指定消息的key值是同一个,采用默认的分区策略,这些消息机会分配到同一个分区实现顺序消费
6.1代码实现
/**
* kafka顺序消费
*/
public SendResult syncSendOrderly(Integer id) throws ExecutionException, InterruptedException {
// 创建 Demo01Message 消息
Demo06Message message = new Demo06Message();
message.setId(id);
message.setContent("kafka顺序消费"+id);
// 同步发送消息
// 因为我们使用 String 的方式序列化 key ,所以需要将 id 转换成 String
// key = String.valueOf(id) 指定为一个固定的值,就会固定分配到主题的一个分区实现顺序消费
return kafkaTemplate.send(Demo06Message.TOPIC, String.valueOf(id), message).get();
}
7.并发消费
- 首先,我们来创建一个 Topic 为
"DEMO_06",并且设置其 Partition 分区数为 10 。 - 然后,我们创建一个 Demo06Consumer 类,并在其消费方法上,添加
@KafkaListener(concurrency=2)注解。 - 再然后,我们启动项目。Spring-Kafka 会根据
@KafkaListener(concurrency=2)注解,创建 2 个 Kafka Consumer 。注意噢,是 2 个 Kafka Consumer 呢!!!后续,每个 Kafka Consumer 会被单独分配到一个线程中,进行拉取消息,消费消息。 - 之后,Kafka Broker 会将 Topic 为
"DEMO_06"分配给创建的 2 个 Kafka Consumer 各 5 个 Partition 。 - 这样,因为
@KafkaListener(concurrency=2)注解,创建 2 个 Kafka Consumer ,就在各自的线程中,拉取各自的 Topic 为"DEMO_06"的 Partition 的消息,各自串行消费。从而,实现多线程的并发消费。
7.1代码实现
消息类
@Data
public class Demo05Message {
public static final String TOPIC = "DEMO_05";
/**
* 编号
*/
private Integer id;
/**
* 内容
*/
private String content;
}
生产者
@Component
public class Demo05Producer {
@Resource
private KafkaTemplate<Object, Object> kafkaTemplate;
/**
* kafka并发消费
* @param id
*/
public SendResult send(Integer id) throws ExecutionException, InterruptedException {
// 创建 Demo05Message 消息
Demo05Message message = new Demo05Message();
message.setId(id);
return kafkaTemplate.send(Demo05Message.TOPIC, message).get();
}
}
消费者
@Component
@Slf4j
public class Demo05Consumer {
@KafkaListener(topics = Demo05Message.TOPIC,
groupId = "demo05-consumer-group-" + Demo05Message.TOPIC,concurrency = "2")
public void onMessage(Demo05Message message) {
log.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), message);
}
}
测试类
@RunWith(SpringRunner.class)
@SpringBootTest(classes = KafkaApplication.class)
@Slf4j
public class Demo05ProducerTest {
@Autowired
private Demo05Producer producer;
@Test
public void testSyncSend() throws ExecutionException, InterruptedException {
for (int i = 0; i < 10; i++) {
int id = (int) (System.currentTimeMillis() / 1000);
SendResult result = producer.send(id);
// log.info("[testSyncSend][发送编号:[{}] 发送结果:[{}]]", id, result);
}
// 阻塞等待,保证消费
new CountDownLatch(1).await();
}
}
8.事务消息
8.1修改应用配置
spring:
# Kafka 配置项,对应 KafkaProperties 配置类
kafka:
bootstrap-servers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
# Kafka Producer 配置项
producer:
acks: all
# acks: 1 # 0-不应答。1-leader 应答。all-所有 leader 和 follower 应答。
retries: 3 # 发送失败时,重试发送的次数
key-serializer: org.apache.kafka.common.serialization.StringSerializer # 消息的 key 的序列化
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer # 消息的 value 的序列化
batch-size: 16384 # 每次批量发送消息的最大数量 16M,默认16k
buffer-memory: 33554432 # 每次批量发送消息的最大内存 32G,默认32M
transaction-id-prefix: demo. # 事务编号前缀
properties:
linger:
ms: 3000 # 批处理延迟时间上限。这里配置为 3 * 1000 ms 过后,不管是否消息数量是否到达 batch-size 或者消息大小到达 buffer-memory 后,都直接发送一次请求。
# Kafka Consumer 配置项
consumer:
auto-offset-reset: earliest # 设置消费者分组最初的消费进度为 earliest 。可参考博客 https://blog.csdn.net/lishuangzhe7047/article/details/74530417 理解
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
fetch-max-wait: 10000 # poll 一次拉取的阻塞的最大时长,单位:毫秒。这里指的是阻塞拉取需要满足至少 fetch-min-size 大小的消息
fetch-min-size: 10 # poll 一次消息拉取的最小数据量,单位:字节
max-poll-records: 100 # poll 一次消息拉取的最大数量
properties:
spring:
json:
trusted:
packages: com.llp.kafka.message
isolation-level: read_committed # 消费者只读取已提交的消息
# Kafka Consumer Listener 监听器配置
listener:
type: batch # 监听器类型,默认为 SINGLE ,只监听单条消息。这里我们配置 BATCH ,监听多条消息,批量消费
missing-topics-fatal: false # 消费监听接口监听的主题不存在时,默认会报错。所以通过设置为 false ,解决报错
logging:
level:
org:
springframework:
kafka: ERROR # spring-kafka INFO 日志太多了,所以我们限制只打印 ERROR 级别
apache:
kafka: ERROR # kafka INFO 日志太多了,所以我们限制只打印 ERROR 级别
- 修改
spring.kafka.producer.acks=all配置,不然在启动时会报"Must set acks to all in order to use the idempotent producer. Otherwise we cannot guarantee idempotence."错误。因为,Kafka 的事务消息需要基于幂等性来实现,所以必须保证所有节点都写入成功。 - 增加
transaction-id-prefix=demo.配置,事务编号的前缀。需要保证相同应用配置相同,不同应用配置不同。 - 增加
spring.kafka.consumer.properties.isolation.level=read_committed配置,Consumer 仅读取已提交的消息。
8.2代码实现
消息类
@Data
public class Demo07Message {
public static final String TOPIC = "DEMO_07";
/**
* 编号
*/
private Integer id;
/**
* 内容
*/
private String content;
}
生产者
@Component
@Slf4j
public class Demo07Producer {
@Resource
private KafkaTemplate<Object, Object> kafkaTemplate;
public String syncSendInTransaction(Integer id, Runnable runner) throws ExecutionException, InterruptedException {
return kafkaTemplate.executeInTransaction(new KafkaOperations.OperationsCallback<Object, Object, String>() {
@Override
public String doInOperations(KafkaOperations<Object, Object> kafkaOperations) {
// 创建 Demo07Message 消息
Demo07Message message = new Demo07Message();
message.setId(id);
try {
SendResult<Object, Object> sendResult = kafkaOperations.send(Demo07Message.TOPIC, message).get();
log.info("[doInOperations][发送编号:[{}] 发送结果:[{}]]", id, sendResult);
} catch (Exception e) {
throw new RuntimeException(e);
}
// 本地业务逻辑... biubiubiu
runner.run();
// 返回结果
return "success";
}
});
}
}
消费者
@Component
@Slf4j
public class Demo07Consumer {
@KafkaListener(topics = Demo07Message.TOPIC,
groupId = "demo07-consumer-group-" + Demo07Message.TOPIC)
public void onMessage(Demo07Message message) {
log.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), message);
}
}
测试类
@RunWith(SpringRunner.class)
@Slf4j
@SpringBootTest(classes = KafkaApplication.class)
public class Demo07ProducerTest {
@Autowired
private Demo07Producer producer;
@Test
public void testSyncSendInTransaction() throws ExecutionException, InterruptedException {
int id = (int) (System.currentTimeMillis() / 1000);
producer.syncSendInTransaction(id, new Runnable() {
@Override
public void run() {
log.info("[run][我要开始睡觉了]");
try {
Thread.sleep(10 * 1000L);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
log.info("[run][我睡醒了]");
}
});
// 阻塞等待,保证消费
new CountDownLatch(1).await();
}
}
测试结果:
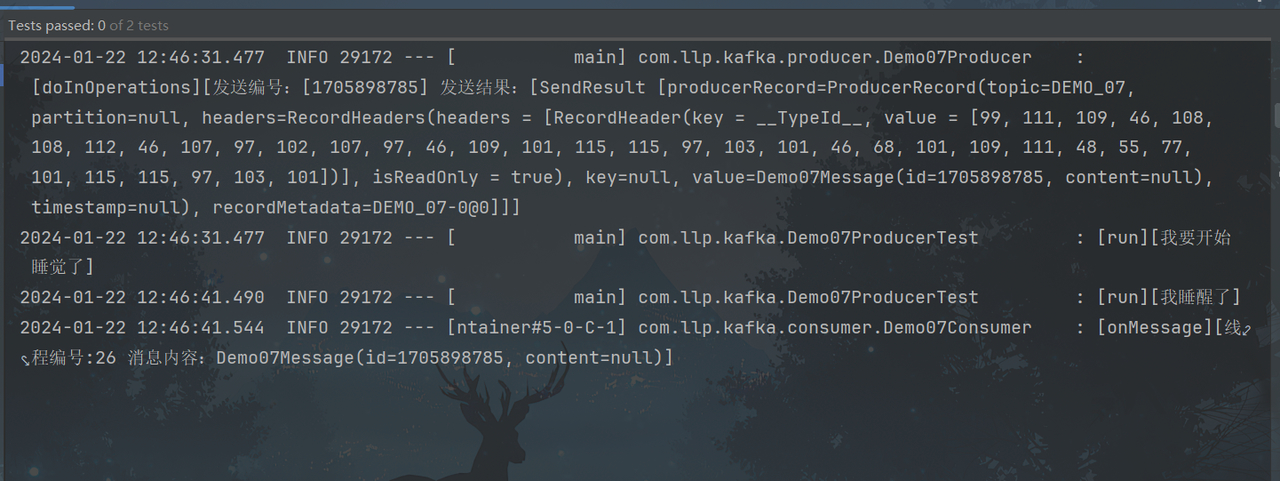
9.消费进度的提交机制
原生 Kafka Consumer 消费端,有两种消费进度提交的提交机制:
- 【默认】自动提交,通过配置
enable.auto.commit=true,每过auto.commit.interval.ms时间间隔,都会自动提交消费消费进度。而提交的时机,是在 Consumer 的#poll(...)方法的逻辑里完成,在每次从 Kafka Broker 拉取消息时,会检查是否到达自动提交的时间间隔,如果是,那么就会提交上一次轮询拉取的位置。 - 手动提交,通过配置
enable.auto.commit=false,后续通过 Consumer 的#commitSync(...)或#commitAsync(...)方法,同步或异步提交消费进度。
Spring-Kafka Consumer 消费端,提供了更丰富的消费者进度的提交机制,更加灵活。当然,也是分成自动提交和手动提交两个大类。在 AckMode 枚举类中,可以看到每一种具体的方式。代码如下:
// ContainerProperties#AckMode.java
public enum AckMode {
// ========== 自动提交 ==========
/**
* Commit after each record is processed by the listener.
*/
RECORD, // 每条消息被消费完成后,自动提交
/**
* Commit whatever has already been processed before the next poll.
*/
BATCH, // 每一次消息被消费完成后,在下次拉取消息之前,自动提交
/**
* Commit pending updates after
* {@link ContainerProperties#setAckTime(long) ackTime} has elapsed.
*/
TIME, // 达到一定时间间隔后,自动提交。
// 不过要注意,它并不是一到就立马提交,如果此时正在消费某一条消息,需要等这条消息被消费完成,才能提交消费进度。
/**
* Commit pending updates after
* {@link ContainerProperties#setAckCount(int) ackCount} has been
* exceeded.
*/
COUNT, // 消费成功的消息数到达一定数量后,自动提交。
// 不过要注意,它并不是一到就立马提交,如果此时正在消费某一条消息,需要等这条消息被消费完成,才能提交消费进度。
/**
* Commit pending updates after
* {@link ContainerProperties#setAckCount(int) ackCount} has been
* exceeded or after {@link ContainerProperties#setAckTime(long)
* ackTime} has elapsed.
*/
COUNT_TIME, // TIME 和 COUNT 的结合体,满足任一都会自动提交。
// ========== 手动提交 ==========
/**
* User takes responsibility for acks using an
* {@link AcknowledgingMessageListener}.
*/
MANUAL, // 调用时,先标记提交消费进度。等到当前消息被消费完成,然后在提交消费进度。
/**
* User takes responsibility for acks using an
* {@link AcknowledgingMessageListener}. The consumer
* immediately processes the commit.
*/
MANUAL_IMMEDIATE, // 调用时,立即提交消费进度。
}
那么,既然现在存在原生 Kafka 和 Spring-Kafka 提供的两种消费进度的提交机制,我们应该怎么配置呢?
- 使用原生 Kafka 的方式,通过配置
spring.kafka.consumer.enable-auto-commit=true。然后,通过spring.kafka.consumer.auto-commit-interval设置自动提交的频率。 - 使用 Spring-Kafka 的方式,通过配置
spring.kafka.consumer.enable-auto-commit=false。然后通过spring.kafka.listener.ack-mode设置具体模式。另外,还有spring.kafka.listener.ack-time和spring.kafka.listener.ack-count可以设置自动提交的时间间隔和消息条数。
默认什么都不配置的情况下,使用 Spring-Kafka 的 BATCH 模式:每一次消息被消费完成后,在下次拉取消息之前,自动提交。
9.1修改应用配置
spring:
# Kafka 配置项,对应 KafkaProperties 配置类
kafka:
bootstrap-servers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
# Kafka Producer 配置项
producer:
acks: 1 # 0-不应答。1-leader 应答。all-所有 leader 和 follower 应答。
retries: 3 # 发送失败时,重试发送的次数
key-serializer: org.apache.kafka.common.serialization.StringSerializer # 消息的 key 的序列化
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer # 消息的 value 的序列化
batch-size: 16384 # 每次批量发送消息的最大数量 16M,默认16k
buffer-memory: 33554432 # 每次批量发送消息的最大内存 32G,默认32M
properties:
linger:
ms: 3000 # 批处理延迟时间上限。这里配置为 3 * 1000 ms 过后,不管是否消息数量是否到达 batch-size 或者消息大小到达 buffer-memory 后,都直接发送一次请求。
# Kafka Consumer 配置项
consumer:
auto-offset-reset: earliest # 设置消费者分组最初的消费进度为 earliest 。可参考博客 https://blog.csdn.net/lishuangzhe7047/article/details/74530417 理解
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
fetch-max-wait: 10000 # poll 一次拉取的阻塞的最大时长,单位:毫秒。这里指的是阻塞拉取需要满足至少 fetch-min-size 大小的消息
fetch-min-size: 10 # poll 一次消息拉取的最小数据量,单位:字节
max-poll-records: 100 # poll 一次消息拉取的最大数量
properties:
spring:
json:
trusted:
packages: com.llp.kafka.message
enable-auto-commit: false
# Kafka Consumer Listener 监听器配置
listener:
# type: batch # 监听器类型,默认为 SINGLE ,只监听单条消息。这里我们配置 BATCH ,监听多条消息,批量消费
missing-topics-fatal: false # 消费监听接口监听的主题不存在时,默认会报错。所以通过设置为 false ,解决报错
ack-mode: manual
logging:
level:
org:
springframework:
kafka: ERROR # spring-kafka INFO 日志太多了,所以我们限制只打印 ERROR 级别
apache:
kafka: ERROR # kafka INFO 日志太多了,所以我们限制只打印 ERROR 级别
- 添加
spring.kafka.consumer.enable-auto-commit=false配置,使用 Spring-Kafka 的消费进度的提交机制。 设计情况下,不添加该配置项也是可以的,因为false是默认值。 - 添加
spring.kafka.listener.ack-mode=MANUAL配置,使用 MANUAL 模式:调用时,先标记提交消费进度。等到当前消息被消费完成,然后在提交消费进度。
9.2代码实现
消息类
@Data
public class Demo08Message {
public static final String TOPIC = "DEMO_08";
/**
* 编号
*/
private Integer id;
/**
* 内容
*/
private String content;
}
生产者
@Component
public class Demo08Producer {
@Resource
private KafkaTemplate<Object, Object> kafkaTemplate;
public SendResult syncSend(Integer id) throws ExecutionException, InterruptedException {
// 创建 Demo08Message 消息
Demo08Message message = new Demo08Message();
message.setId(id);
// 同步发送消息
return kafkaTemplate.send(Demo08Message.TOPIC, message).get();
}
}
消费者
@Component
@Slf4j
public class Demo08Consumer {
@KafkaListener(topics = Demo08Message.TOPIC,
groupId = "demo08-consumer-group-" + Demo08Message.TOPIC)
public void onMessage(Demo08Message message, Acknowledgment acknowledgment) {
// 提交消费进度
if (message.getId() % 2 == 1) {
//手动ack,确认消息被消费
log.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), message);
acknowledgment.acknowledge();
}
}
}
- 在消费方法上,我们增加了第二个方法参数,类型为 Acknowledgment类。通过调用其
#acknowledge()方法,可以提交当前消息的 Topic 的 Partition 的消费进度。 - 在消费逻辑中,我们故意只提交消费的消息的
Demo08Message.id为奇数的消息。这样,我们只需要发送一条id=1,一条id=2的消息,如果第二条的消费进度没有被提交,就可以说明手动提交消费进度成功。
测试类
@RunWith(SpringRunner.class)
@SpringBootTest(classes = KafkaApplication.class)
@Slf4j
public class Demo08ProducerTest {
@Autowired
private Demo08Producer producer;
@Test
public void testSyncSend() throws ExecutionException, InterruptedException {
for (int id = 1; id <= 2; id++) {
SendResult result = producer.syncSend(id);
log.info("[testSyncSend][发送编号:[{}] 发送结果:[{}]]", id, result);
}
// 阻塞等待,保证消费
new CountDownLatch(1).await();
}
}
测试结果
// 消息id为1
2024-01-22 13:05:42.140 INFO 22000 --- [ main] com.llp.kafka.Demo08ProducerTest : [testSyncSend][发送编号:[1] 发送结果:[SendResult [producerRecord=ProducerRecord(topic=DEMO_08, partition=null, headers=RecordHeaders(headers = [RecordHeader(key = __TypeId__, value = [99, 111, 109, 46, 108, 108, 112, 46, 107, 97, 102, 107, 97, 46, 109, 101, 115, 115, 97, 103, 101, 46, 68, 101, 109, 111, 48, 56, 77, 101, 115, 115, 97, 103, 101])], isReadOnly = true), key=null, value=Demo08Message(id=1, content=null), timestamp=null), recordMetadata=DEMO_08-0@8]]]
// 消息id为1 1%2 == 1 被确认消费
2024-01-22 13:05:42.141 INFO 22000 --- [ntainer#6-0-C-1] com.llp.kafka.consumer.Demo08Consumer : [onMessage][线程编号:16 消息内容:Demo08Message(id=1, content=null)]
// 消息id为2 2%2 !=1 消费进度没有提交
2024-01-22 13:05:45.148 INFO 22000 --- [ main] com.llp.kafka.Demo08ProducerTest : [testSyncSend][发送编号:[2] 发送结果:[SendResult [producerRecord=ProducerRecord(topic=DEMO_08, partition=null, headers=RecordHeaders(headers = [RecordHeader(key = __TypeId__, value = [99, 111, 109, 46, 108, 108, 112, 46, 107, 97, 102, 107, 97, 46, 109, 101, 115, 115, 97, 103, 101, 46, 68, 101, 109, 111, 48, 56, 77, 101, 115, 115, 97, 103, 101])], isReadOnly = true), key=null, value=Demo08Message(id=2, content=null), timestamp=null), recordMetadata=DEMO_08-0@9]]]